Page Not Found
Page not found. Your pixels are in another canvas.

A list of all the posts and pages found on the site. For you robots out there is an XML version available for digesting as well.
Page not found. Your pixels are in another canvas.
About me
This is a page not in th emain menu
Published:
This post will show up by default. To disable scheduling of future posts, edit config.yml and set future: false.
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Published:
This post describes the recent work on unsupervised domain adaptation for semantic segmentation presented at CVPR 2019. ADVENT is a flexible technique for bridging the gap between two different domains through entropy minimization. Our work builds upon a simple observation: models trained only on source domain tend to produce over-confident, i.e., low-entropy, predictions on source-like images and under-confident, i.e., high-entropy, predictions on target-like ones. Consequently by minimizing the entropy on the target domain, we make the feature distributions from the two domains more similar. We show that our approach achieves competitive performances on standard semantic segmentation benchmarks and that it can be successfully extended to other tasks such as object detection.
Published:
In a vehicle license plate identification system, plate region detection is the crucial step before the ultimate recognition. In most of the traffic-related applications such as searching of stolen vehicles, road traffic monitoring, airport gate monitoring, speed checking and parking access control. This paper is focused on license plate detection, license plate detection in this paper is based on mathematical morphology and considers features like license plate width, height, ratio, and angle. The advantage of the proposed system is that it works for all types of license plates which differ in size and shapes. The proposed system archived promising results.
Recommended citation: Ihsan Ullah et al. (2016). An Approach of Locating Korean Vehicle License Plate Based on Mathematical Morphology and Geometrical Features; 2016 International Conference on Computational Science and Computational Intelligence (CSCI).. 1(1). https://ieeexplore.ieee.org/document/7881455
Published:
In automatic video monitoring, real-time detection and in particular shadow elimination are critical to the correct moving objects segmentation since they severely affect the surveillance process. In this paper, we put forward a rapid and flexible approach in which vehicles detection is based on the Gaussian Mixture Model and shadow elimination is based on morphology and edge detection. Experimental results show that the technique achieved promising accuracy.
Recommended citation: Ihsan Ullah et al. (2016). An Effective Algorithm for Shadow Removal from Moving Vehicles Based on Morphology; 2016 International Symposium on Information Technology Convergence.. 1(1). https://ihsan149.github.io/files/c5.pdf
Published:
Moving object detection is a task to identify the physical motion of an object in a specific region or area. Over the last few years, moving object detection has received much attention due to its wide range of applications like video surveillance, human motion analysis, robot navigation, event detection, anomaly detection, video conferencing, traffic analysis and security. In this paper, a framework is proposed for the evaluation of object detection algorithms in surveillance applications using background subtraction and Mixture of Gaussian. Experimental results show that our technique achieved promising accuracy.
Recommended citation: Ihsan Ullah et al. (2016). Moving Object Detection Based on Background Subtraction; 2016 Conference of KIISE, South Korea.. 1(1). https://ihsan149.github.io/files/c6.pdf
Published:
Rapid advancement of technology in artificial intelligence and computer science knowledge and then feel the need to search and secure automated systems are because of the appearance of intelligent systems based on image processing and spread this knowledge. One of these intelligent systems is license plate recognition (LPR) system. LPR plays an important role in intelligent transportation system; however, plate region extraction is the key step before the final recognition. In this paper, an effective license plate extraction algorithm is proposed based on geometrical features and multilevel thresholding to identify and segment the license plate from the image. Experimental results show that the technique achieved promising accuracy.
Recommended citation: Ihsan Ullah et al. (2016). License Plate Detection Based on Rectangular Features and Multilevel Thresholding; 2016 IPCV.. 1(1). https://ihsan149.github.io/files/c7.pdf
Published:
In recent years, vehicle recognition has become an important application in intelligent traffic monitoring and management. Vehicle analysis is an essential component in many intelligent applications, such as automatic toll collection, driver assistance systems, self-guided vehicles, intelligent parking systems, and traffic statistics (vehicle count, speed, and flow). The main goal of our study is to extract the information from the moving vehicles like their make, model and type. We address the vehicle detection and recognition problems using Deep Neural Networks (DNNs) approach. Our proposed approach outperforms state-of-the-art method. We first detect the moving vehicle based on frame difference and then extract the frontal part of the vehicle based on symmetrical filter, the frontal part of the vehicle is fed into the deep architecture for recognition. The Top 1 accuracy of proposed VMMTR algorithm is 96.31%.Our method achieves promising results on image.
Recommended citation: Ihsan Ullah et al. (2017). Moving Vehicle Detection and Information Extraction Based on Deep Neural Network; 2017 Proceedings of the International Conference on Image Processing, Computer Vision, and Pattern Recognition (IPCV); Athens, (2017).. 1(1). https://ihsan149.github.io/files/c3.pdf
Published:
Accurate localization of catheters or guidewires in fluoroscopy images is important to improve the stability of intervention procedures as well as the development of surgical navigation systems. Recently, deep learning methods have been proposed to improve performance, however these techniques require extensive pixel-wise annotations. Moreover, the human annotation effort is equally expensive. In this study, we mitigate this labeling effort using generative adversarial networks (cycleGAN) wherein we synthesize realistic catheters in flouroscopy from localized guidewires in camera images whose annotations are cheaper to acquire. Our approach is motivated by the fact that catheters are tubular structures with varying profiles, thus given a guidewire in a camera image, we can obtain the centerline that follows the profile of a catheter in an X-ray image and create plausible X-ray images composited with such a centerline. In order to generate an image similar to the actual X-ray image, we propose a loss term that includes perceptual loss alongside the standard cycle loss. Experimental results show that the proposed method has better performance than the conventional GAN and generates images with consistent quality. Further, we provide evidence to the development of methods that leverage such synthetic composite images in supervised settings.
Recommended citation: Ihsan Ullah et al. (2019). Catheter Synthesis in X-Ray Fluoroscopy with Generative Adversarial Networks; MICCAI PRIME. 1(1). https://link.springer.com/content/pdf/10.1007/978-3-030-32281-6_13.pdf?pdf=inline%20link
Published:
In recent years, research has been carried out using a micro-robot catheter instead of classic cardiac surgery performed using a catheter. To accurately control the micro-robot catheter, accurate and decisive tracking of the guidewire tip is required. In this paper, we propose a method based on the deep convolutional neural network (CNN) to track the guidewire tip. To extract a very small tip region from a large image in video sequences, we first segment small tip candidates using a segmentation CNN architecture, and then extract the best candidate using shape and motion constraints. The segmentation-based tracking strategy makes the tracking process robust and sturdy. The tracking of the guidewire tip in video sequences is performed fully-automated in real-time, i.e., 71 ms per image. For two-fold cross-validation, the proposed method achieves the average Dice score of 88.07% and IoU score of 85.07%.
Recommended citation: Ihsan Ullah et al. (2019). Guidewire Tip Tracking using U-Net with Shape and Motion Constraints; 2019 International Conference on Artificial Intelligence in Information and Communication (ICAIIC). 1(1). https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=8669088
Unsupervised domain adaptation (UDA) techniques address domain shift and allow deep neural networks to be used for various tasks. Although several image UDA methods have been presented, video-based UDA has received less attention. This is due to the complexity involved in adapting diverse modalities of video features, such as the long-term dependency of temporally associated pixels. Existing methods often use optical flow to capture motion information between consecutive frames of the same domain, however, leveraging optical flow across images in different domains is challenging, and generally, the computation is heavy. In this work, we propose adversarial domain adaptation for video semantic segmentation by aligning temporally associated pixels in successive source and target frames. More specifically, we identify perceptually similar pixels with the highest correlation across consecutive frames and infer that such pixels correspond to the same class. Perceptual consistency matching (PCM) on successive frames within the same and across domains enables to capture temporal consistency and improves prediction accuracy. In addition, our method achieves faster inference time without using optical flow. Extensive experiments on public datasets demonstrate our method outperforms existing state-of-the-art video-based UDA approaches.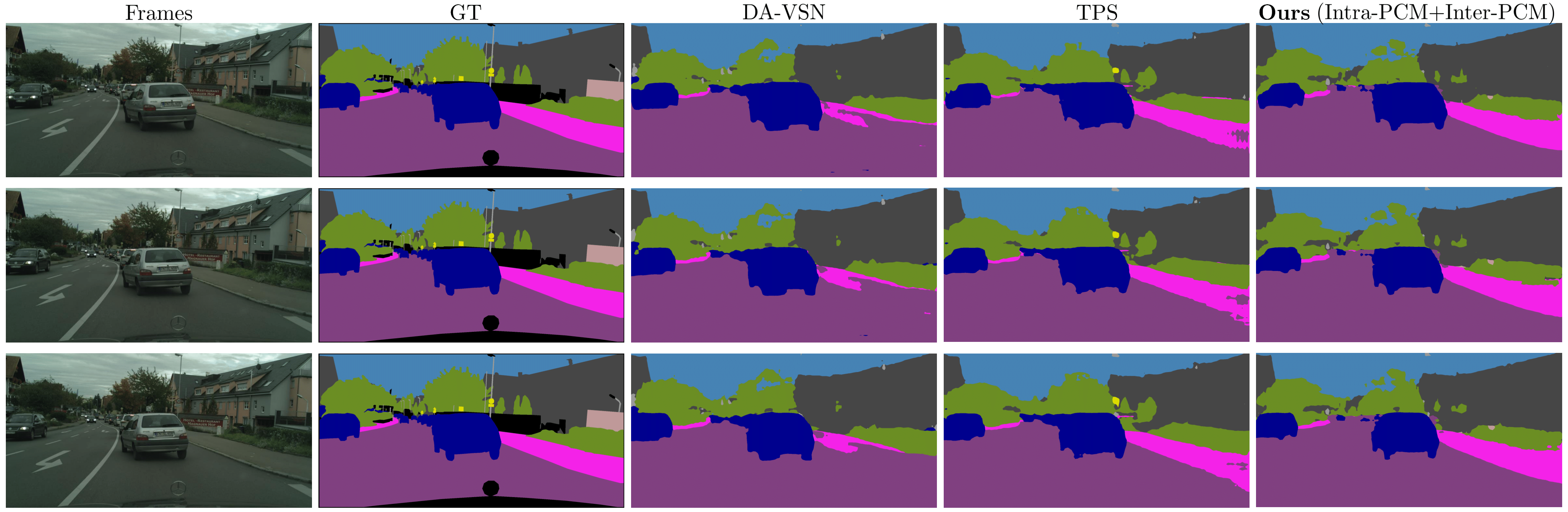
In this work, we introduce a comprehensive framework designed to utilize the power of temporal information for precise drone tracking within infrared (IR) video sequences. We have integrated temporal information at two stages: feature extraction and similarity map enhancement. In the stage of feature extraction, we employ an online, temporally adaptive convolution approach that leverages temporal information to augment spatial features. This enhancement is achieved by dynamically adjusting convolution weights based on previous frame data. As for refining the similarity map, our method utilizes an adaptive temporal transformer. This transformer efficiently encodes temporal insights and subsequently decodes this knowledge to fine-tune the similarity map, ensuring accurate tracking results.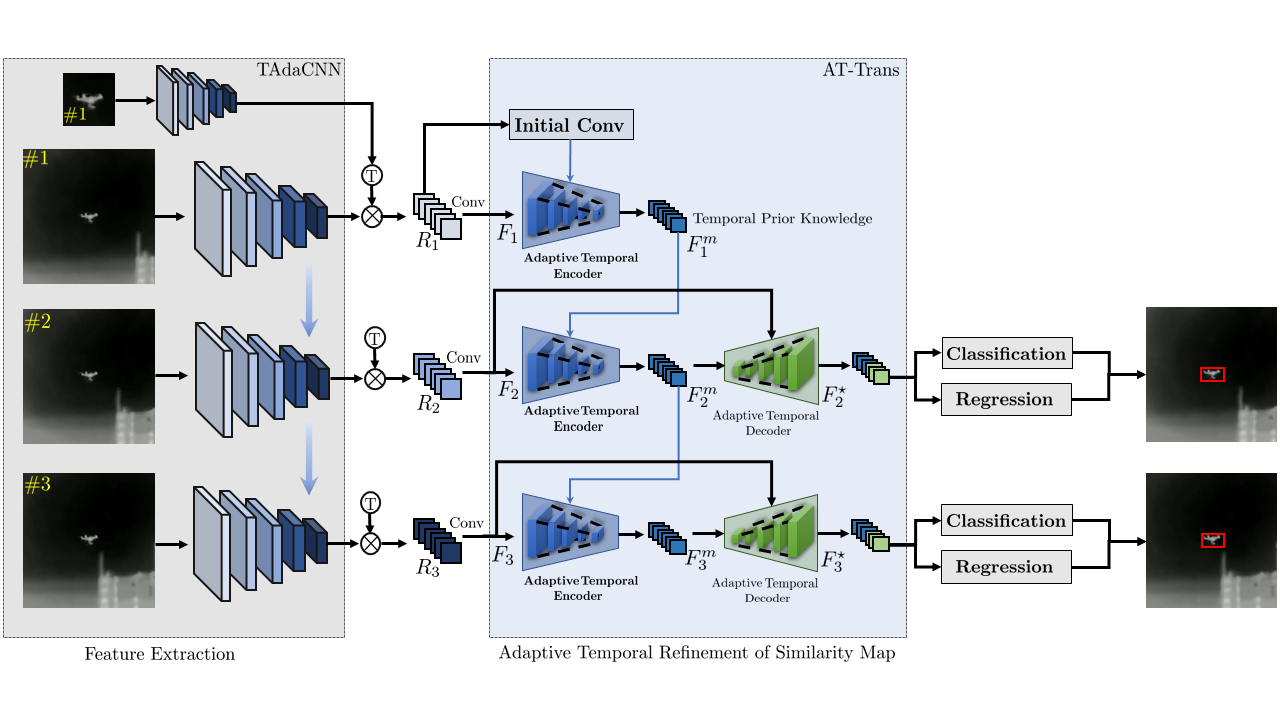
Unauthorized mobile screen recordings pose a serious threat to the security and privacy of personal computers in today’s digital era. Nevertheless, there is a lack of prior research conducted to address this particular challenge. To tackle this challenge, we present a deep learning approach that effectively manipulates the channels in the temporal dimension in video frames. The channel manipulation in temporal dimension allows the mixing of feature maps from adjacent frames with the current frame, resulting in improved mobile action recognition in videos. Moreover, the Mobilenetv2 architecture incorporates the channel shifting module after the bypass connections. In addition, the proposed method employs the Mobilenetv2 architecture, resulting in improved computational efficiency for frame processing. Consequently, it is well-suited for real-time recognition of unauthorized mobile screen recording, with low latency.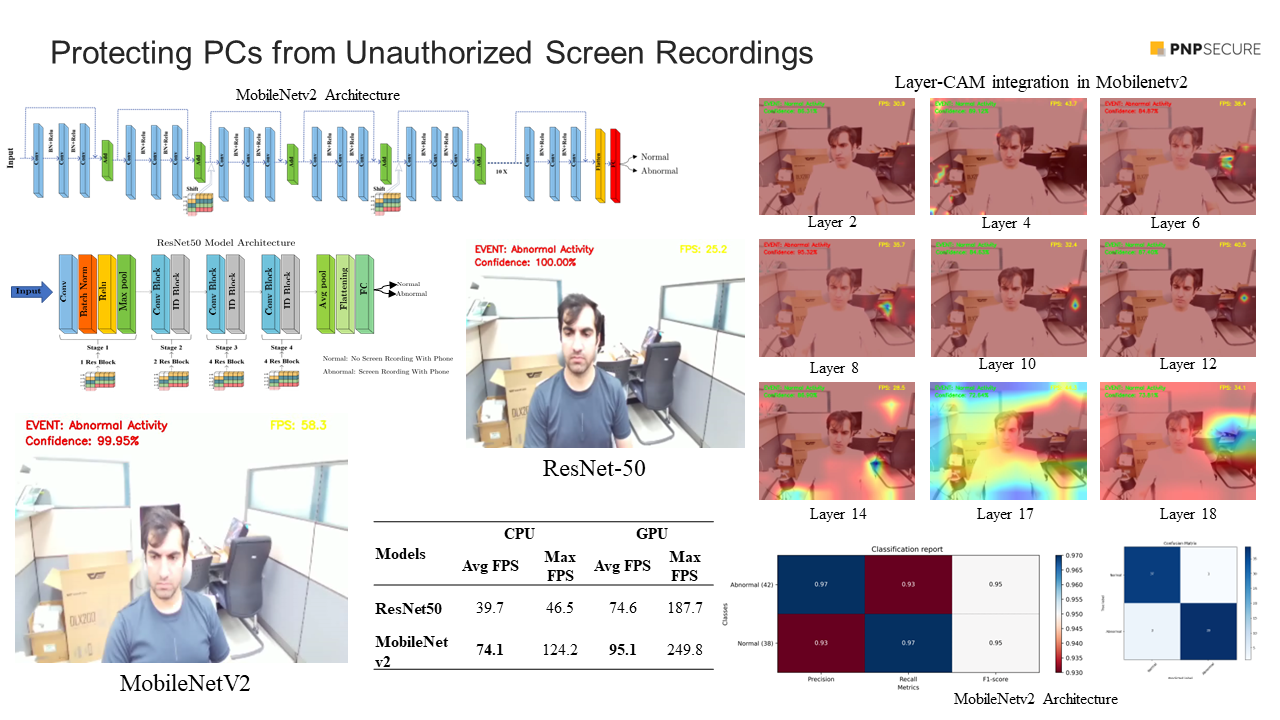
A Deep Learning-based Annotation Tool for Medical Images is an AI-powered tool that assists in the annotation process of medical images, making it faster and more accurate. The tool utilizes deep learning algorithms to make predictions about the annotations, but also allows for manual adjustments. This semi-automatic approach balances automation and manual intervention to ensure accurate and reliable annotations. This tool is an efficient and valuable tool for medical professionals, helping them make informed decisions for their patients.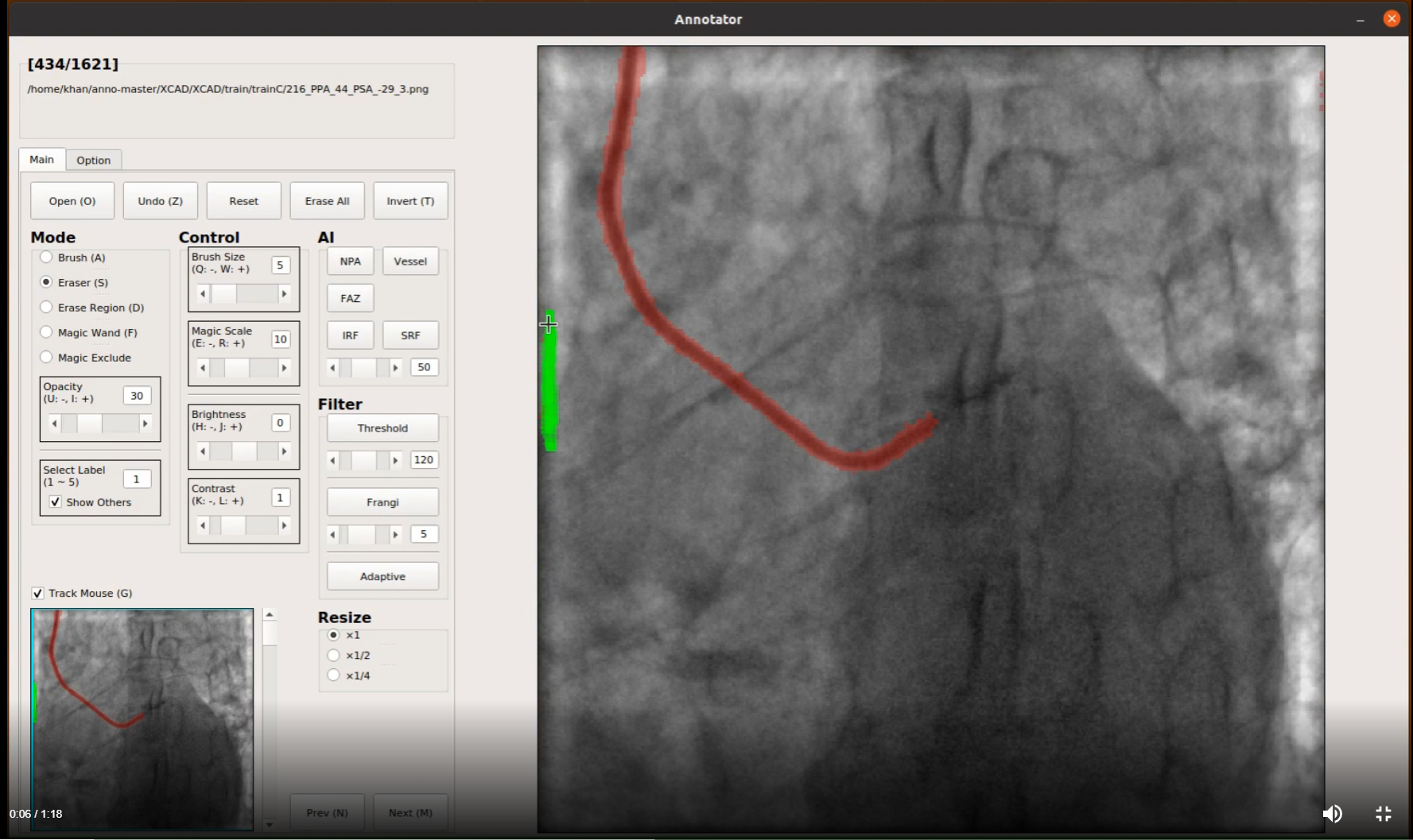
A Deep Learning based Vehicle Recognition System uses artificial neural networks and computer vision to accurately identify and classify different types of vehicles in real-time. Developed using Caffe, C++, and QT, this system has applications in transportation and security, such as traffic management and road safety. The system is trained on large datasets of vehicle images and recognizes various types of vehicles using a convolutional neural network model. This technology has the potential to revolutionize the field of transportation and security. 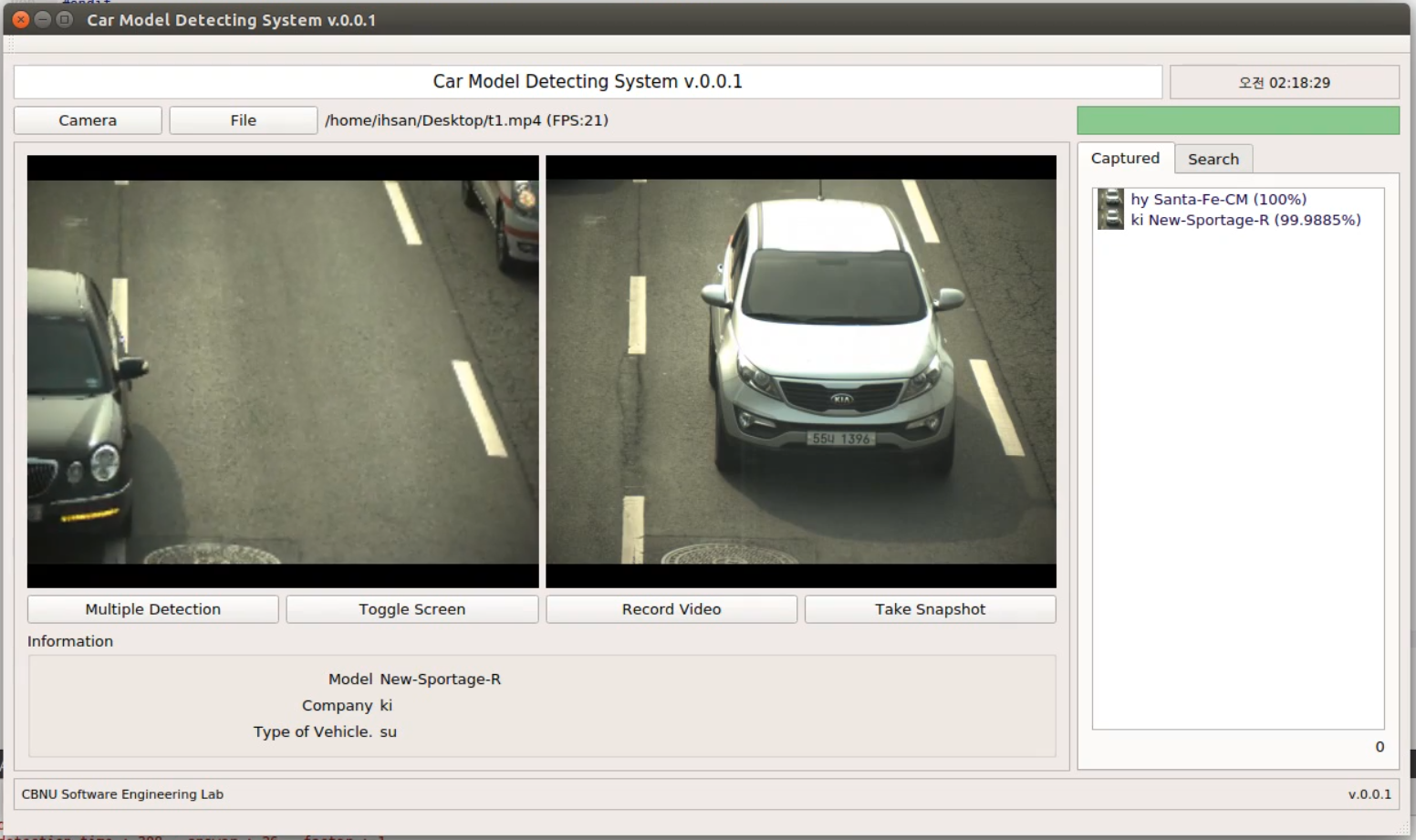
Published:
Domain adaptation (DA) techniques address domain shift and allow deep neural networks to be used for a variety of tasks. Although several image DA methods have been presented, video-based DA has received less attention. This is due to the complexity involved in adapting diverse modalities of video features, such as the long-term dependency of temporally associated pixels. In this work, we propose adversarial domain adaptation for video semantic segmentation by aligning temporally associated pixels in successive source and target frames. More specifically, we identify perceptually similar pixels with the highest correlation across successive frames, and infer that such pixels correspond to the same class. By employing perceptual consistency matching (PCM) for successive frames within the same domain and across domains, the proposed method is able to capture temporal consistency and assist the model in correcting pixel predictions. Extensive experiments on public datasets demonstrate our method can outperform existing state-of-the-art video-based UDA approaches.
Recommended citation: Ihsan Ullah et al. (2022). Video Domain Adaptation for Semantic Segmentation.(ESWA)</i>
Published in Frontiers in Plant Science, 2009
Plants contribute significantly to the global food supply. Various Plant diseases can result in production losses, which can be avoided by maintaining vigilance. However, manually monitoring plant diseases by agriculture experts and botanists is time-consuming, challenging and error-prone. To reduce the risk of disease severity, machine vision technology (i.e., artificial intelligence) can play a significant role. In the alternative method, the severity of the disease can be diminished through computer technologies and the cooperation of humans. These methods can also eliminate the disadvantages of manual observation. In this work, we proposed a solution to detect tomato plant disease using a deep leaning-based system utilizing the plant leaves image data. We utilized an architecture for deep learning based on a recently developed convolutional neural network that is trained over 18,161 segmented and non-segmented tomato leaf images—using a supervised learning approach to detect and recognize various tomato diseases using the Inception Net model in the research work. For the detection and segmentation of disease-affected regions, two state-of-the-art semantic segmentation models, i.e., U-Net and Modified U-Net, are utilized in this work. The plant leaf pixels are binary and classified by the model as Region of Interest (ROI) and background. There is also an examination of the presentation of binary arrangement (healthy and diseased leaves), six-level classification (healthy and other ailing leaf groups), and ten-level classification (healthy and other types of ailing leaves) models. The Modified U-net segmentation model outperforms the simple U-net segmentation model by 98.66 percent, 98.5 IoU score, and 98.73 percent on the dice. InceptionNet1 achieves 99.95% accuracy for binary classification problems and 99.12% for classifying six segmented class images; InceptionNet outperformed the Modified U-net model to achieve higher accuracy. The experimental results of our proposed method for classifying plant diseases demonstrate that it outperforms the methods currently available in the literature.
Recommended citation: Ihsan Ullah et al. (2022). Deep learning-based segmentation and classification of leaf images for detection of tomato plant disease; Frontiers in Plant Science. 1(1). https://ihsan149.github.io/files/fpls.pdf
Published in Applied Sciences, 2009
Automatic catheter and guidewire segmentation plays an important role in robot-assisted interventions that are guided by fluoroscopy. Existing learning based methods addressing the task of segmentation or tracking are often limited by the scarcity of annotated samples and difficulty in data collection. In the case of deep learning based methods, the demand for large amounts of labeled data further impedes successful application. We propose a synthesize and segment approach with plug in possibilities for segmentation to address this. We show that an adversarially learned image-to-image translation network can synthesize catheters in X-ray fluoroscopy enabling data augmentation in order to alleviate a low data regime. To make realistic synthesized images, we train the translation network via a perceptual loss coupled with similarity constraints. Then existing segmentation networks are used to learn accurate localization of catheters in a semi-supervised setting with the generated images. The empirical results on collected medical datasets show the value of our approach with significant improvements over existing translation baseline methods.
Recommended citation: Ihsan Ullah et al. (2021). Synthesize and Segment: Towards Improved Catheter Segmentation via Adversarial Augmentation; Applied Sciences. 1(1). https://ihsan149.github.io/files/catheter_synthesis.pdf
Published in IEEE Access, 2019
Studies are proceeded to stabilize cardiac surgery using thin micro-guidewires and catheter robots. To control the robot to a desired position and pose, it is necessary to accurately track the robot tip in real time but tracking and accurately delineating the thin and small tip is challenging. To address this problem, a novel image analysis-based tracking method using deep convolutional neural networks (CNN) has been proposed in this paper. The proposed tracker consists of two parts; (1) a detection network for rough detection of the tip position and (2) a segmentation network for accurate tip delineation near the tip position. To learn a robust real-time tracker, we extract small image patches, including the tip in successive frames and then learn the informative spatial and motion features for the segmentation network. During inference, the tip bounding box is first estimated in the initial frame via the detection network, thereafter tip delineation is consecutively performed through the segmentation network in the following frames. The proposed method enables accurate delineation of the tip in real time and automatically restarts tracking via the detection network when tracking fails in challenging frames. Experimental results show that the proposed method achieves better tracking accuracy than existing methods, with a considerable real-time speed of 19ms.
Recommended citation: Ihsan Ullah et al. (2019). Real-Time Tracking of Guidewire Robot Tips Using Deep Convolutional Neural Networks on Successive Localized Frames; IEEE Access. 1(1). https://ihsan149.github.io/files/catheter_tracking.pdf
Published in Sensors, 2019
Make and model recognition (MMR) of vehicles plays an important role in automatic vision-based systems. This paper proposes a novel deep learning approach for MMR using the SqueezeNet architecture. The frontal views of vehicle images are first extracted and fed into a deep network for training and testing. The SqueezeNet architecture with bypass connections between the Fire modules, a variant of the vanilla SqueezeNet, is employed for this study, which makes our MMR system more efficient. The experimental results on our collected large-scale vehicle datasets indicate that the proposed model achieves 96.3% recognition rate at the rank-1 level with an economical time slice of 108.8 ms. For inference tasks, the deployed deep model requires less than 5 MB of space and thus has a great viability in real-time applications.
Recommended citation: Ihsan Ullah et al. (2019). Real-Time Vehicle Make and Model Recognition with the Residual SqueezeNet Architecture; Sensons. 1(1). https://ihsan149.github.io/files/vehicle_type.pdf
Published in Computers, Materials & Continua, 2021
Recent advancements in hardware and communication technologies have enabled worldwide interconnection using the internet of things (IoT). The IoT is the backbone of smart city applications such as smart grids and green energy management. In smart cities, the IoT devices are used for linking power, price, energy, and demand information for smart homes and home energy management (HEM) in the smart grids. In complex smart grid-connected systems, power scheduling and secure dispatch of information are the main research challenge. These challenges can be resolved through various machine learning techniques and data analytics. In this paper, we have proposed a particle swarm optimization based machine learning algorithm known as a collaborative execute-before-after dependency-based requirement, for the smart grid. The proposed collaborative execute-before-after dependency-based requirement algorithm works in two phases, analysis and assessment of the requirements of end-users and power distribution companies. In the first phases, a fixed load is adjusted over a period of 24 h, and in the second phase, a randomly produced population load for 90 days is evaluated using particle swarm optimization. The simulation results demonstrate that the proposed algorithm performed better in terms of percentage cost reduction, peak to average ratio, and power variance mean ratio than particle swarm optimization and inclined block rate.
Recommended citation: Ihsan Ullah et al. (2021). Machine Learning-Enabled Power Scheduling in IoT-Based Smart Cities; Computers, Materials & Continua . 1(1). https://ihsan149.github.io/files/iot.pdf
Published in Diagnostics, 2022
Confocal microscopy image analysis is a useful method for neoplasm diagnosis. Many ambiguous cases are difficult to distinguish with the naked eye, thus leading to high inter-observer variability and significant time investments for learning this method. We aimed to develop a deep learning-based neoplasm classification model that classifies confocal microscopy images of 10× magnified colon tissues into three classes: neoplasm, inflammation, and normal tissue. ResNet50 with data augmentation and transfer learning approaches was used to efficiently train the model with limited training data. A class activation map was generated by using global average pooling to confirm which areas had a major effect on the classification. The proposed method achieved an accuracy of 81%, which was 14.05% more accurate than three machine learning-based methods and 22.6% better than the predictions made by four endoscopists. ResNet50 with data augmentation and transfer learning can be utilized to effectively identify neoplasm, inflammation, and normal tissue in confocal microscopy images. The proposed method outperformed three machine learning-based methods and identified the area that had a major influence on the results. Inter-observer variability and the time required for learning can be reduced if the proposed model is used with confocal microscopy image analysis for diagnosis.
Recommended citation: Ihsan Ullah et al. (2022). Classification of the Confocal Microscopy Images of Colorectal Tumor and Inflammatory Colitis Mucosa Tissue Using Deep Learning; Diagnostics. 1(1). https://ihsan149.github.io/files/confocal_microscopy.pdf
Published in Scientific Reports, 2023
Automated multi-organ segmentation plays an essential part in the computer-aided diagnostic (CAD) of chest X-ray fluoroscopy. However, developing a CAD system for the anatomical structure segmentation remains challenging due to several indistinct structures, variations in the anatomical structure shape among different individuals, the presence of medical tools, such as pacemakers and catheters, and various artifacts in the chest radiographic images. In this paper, we propose a robust deep learning segmentation framework for the anatomical structure in chest radiographs that utilizes a dual encoder–decoder convolutional neural network (CNN). The first network in the dual encoder–decoder structure effectively utilizes a pre-trained VGG19 as an encoder for the segmentation task. The pre-trained encoder output is fed into the squeeze-and-excitation (SE) to boost the network’s representation power, which enables it to perform dynamic channel-wise feature calibrations. The calibrated features are efficiently passed into the first decoder to generate the mask. We integrated the generated mask with the input image and passed it through a second encoder–decoder network with the recurrent residual blocks and an attention the gate module to capture the additional contextual features and improve the segmentation of the smaller regions. Three public chest X-ray datasets are used to evaluate the proposed method for multi-organs segmentation, such as the heart, lungs, and clavicles, and single-organ segmentation, which include only lungs. The results from the experiment show that our proposed technique outperformed the existing multi-class and single-class segmentation methods.
Recommended citation: Ihsan Ullah et al. (2023). A deep learning based dual encoder–decoder framework for anatomical structure segmentation in chest X-ray images; Scientific Reports. 1(1). https://www.nature.com/articles/s41598-023-27815-w
Published:
This is a description of your conference proceedings talk, note the different field in type. You can put anything in this field.
Published:
Webinar on Synthesize and Segment: Towards Improved Interventional Medical Robot (Catheter/Guidewire) Segmentation via Adversarial Learning.
Published:
| Video Examples |
|---|
Cousres, DGIST, Robotics and Mechatronics Engineering, 2015
I was a teaching assistant for Professor Sang Hyun Park’s Machine Learning class at the Department of Robotics and Mechatronics Engineering, DGIST, which was a graduate-level course lasting 15 weeks. My role as a TA involved grading assignments and exams, leading review sessions, and providing individualized feedback to students. I was also responsible for delivering mini-lectures on specific topics and conducting lab experiments to help students understand complex concepts.