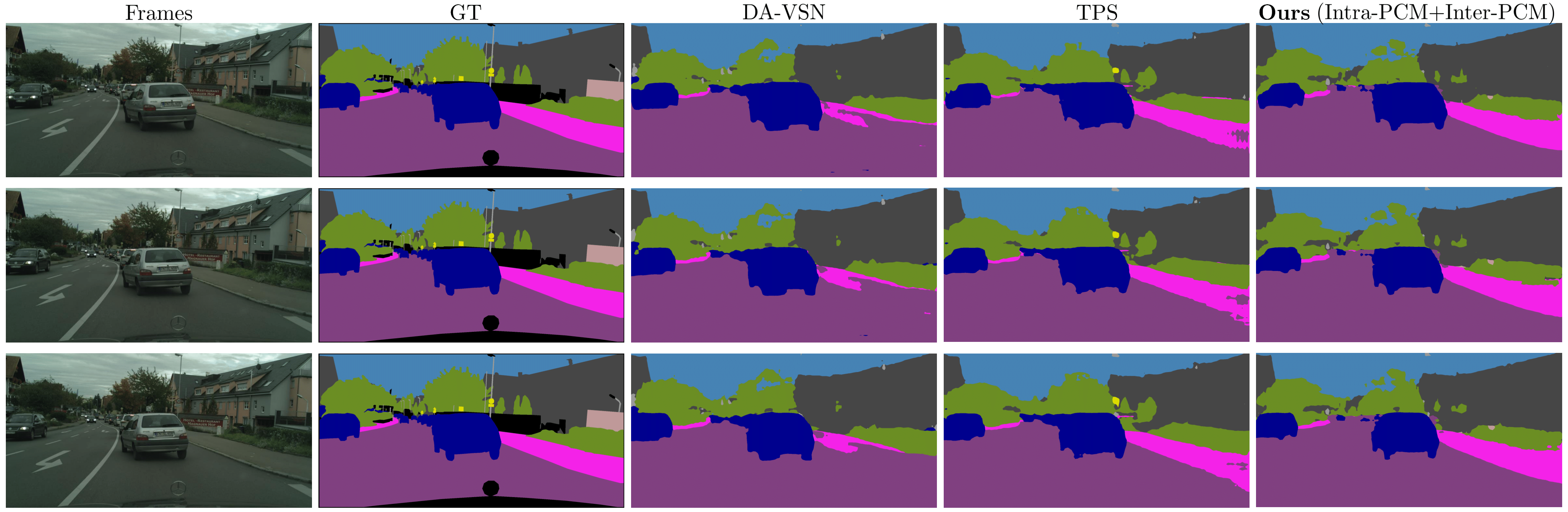
Video Domain Adaptation for Semantic Segmentation
Unsupervised domain adaptation (UDA) techniques address domain shift and allow deep neural networks to be used for various tasks. Although several image UDA methods have been presented, video-based UDA has received less attention. This is due to the complexity involved in adapting diverse modalities of video features, such as the long-term dependency of temporally associated pixels. Existing methods often use optical flow to capture motion information between consecutive frames of the same domain, however, leveraging optical flow across images in different domains is challenging, and generally, the computation is heavy. In this work, we propose adversarial domain adaptation for video semantic segmentation by aligning temporally associated pixels in successive source and target frames. More specifically, we identify perceptually similar pixels with the highest correlation across consecutive frames and infer that such pixels correspond to the same class. Perceptual consistency matching (PCM) on successive frames within the same and across domains enables to capture temporal consistency and improves prediction accuracy. In addition, our method achieves faster inference time without using optical flow. Extensive experiments on public datasets demonstrate our method outperforms existing state-of-the-art video-based UDA approaches.